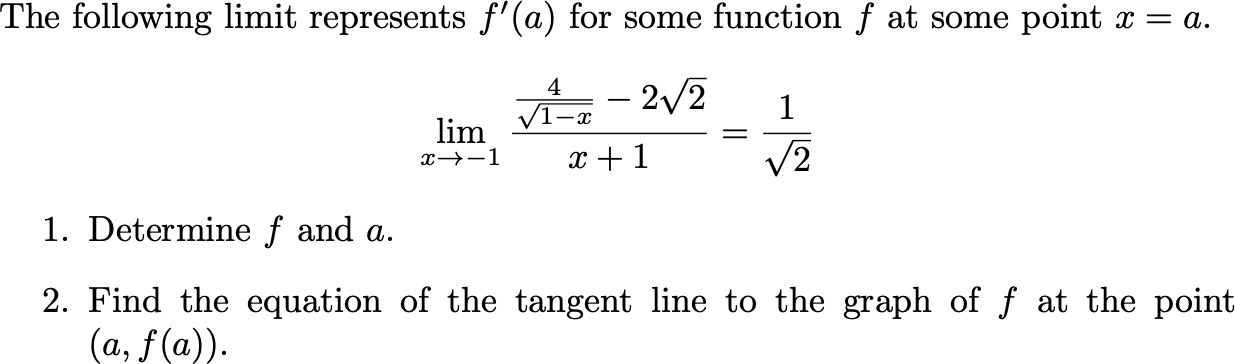The history of programming languages can be seen as a progressive
movement away from catering primarily to machines and toward catering to
humans. Early programming involved machine languages and
assembly. Later came higher-level languages such as Fortran and
COBOL, followed by paradigms such as structured programming,
object-oriented programming, and functional
programming.
Recently, some have argued that the culmination of this trend—in the
age of large language models (LLMs) and AI agents—is the promotion of
natural language (e.g., English) as the universal
programming language. In this view, programming becomes the task of
describing desired behavior in natural language, while the LLM generates
the corresponding code.
Nevertheless, LLMs still need to produce code in some
concrete programming language. Natural language may
describe the intent, but software systems ultimately run on formal
programs.
Two natural questions arise:
Is there a best choice for the programming language that
LLMs should target?
Is natural language alone really sufficient for writing precise
specifications?
In this post I argue that using a functional programming
language—or at least a language that strongly supports the
functional paradigm—as the LLM’s target language has several advantages
when turning a natural-language specification into correct, maintainable,
and auditable code. I will focus on Haskell, both as a
representative functional language and as a language whose design strongly
emphasizes correctness and expressiveness.
Haskell as an Excellent LLM
Target
In essence, Haskell is very good at turning “what you meant”
into “what the compiler can check.”
Several characteristics make it particularly well suited as a target
language for machine-generated code.
1)
The Type System Becomes a Second Verifier of the LLM’s Output
LLMs are very good at producing plausible code, but
they offer no guarantee that the code is correct.
Haskell’s type system allows the human programmer to force the LLM to
commit to precise contracts:
Algebraic data types make illegal states
unrepresentable.
Newtypes prevent unit mix-ups (“UserId vs Email”,
“Milliseconds vs Seconds”).
Sum types force explicit handling of cases instead
of silently “defaulting”.
When the code does not typecheck, the compiler often produces
actionable feedback (e.g. “you forgot this branch”, “this
function expects UserId but you passed
Text”).
This is extremely valuable in an LLM-assisted workflow, because it
creates a tight feedback loop:
generate → compile → refine until the types line
up
The type system becomes a second verification layer for
machine-generated code.
2)
Purity and Referential Transparency Make Behavior Easier to Specify and
Test
In Haskell, most logic can be expressed as pure
functions.
Natural-language specifications often follow the structure:
“Given input X, produce output Y, while maintaining certain
invariants.”
Pure functions map almost perfectly to this pattern.
Pure code also has fewer hidden dependencies:
no implicit access to time
no global mutable state
no implicit IO
This makes the code:
easier for an LLM to generate without accidentally introducing side
effects,
easier for humans to review,
easier to test (unit tests resemble mathematical equalities).
3)
Equational Reasoning and Compositionality Match How Humans Describe
Systems
Humans naturally describe computation as pipelines:
“Parse → validate → normalize → compute → format → return errors if
needed.”
Haskell’s function composition, higher-order functions, and
expressive type system match this mental model closely. An LLM can often
translate a bullet-point specification into a composition of small
functions with clear types.
This compositional style also tends to produce modular and
maintainable code.
4) Error Handling by
Construction
In many mainstream software stacks, error handling is optional and
often added later.
In Haskell, types often force error handling into the design from the
beginning:
Either DomainError a explicitly represents
failure.
NonEmpty ensures that a collection cannot be
empty.
Optional values use Maybe instead of
null.
Validated values can be represented with distinct types.
This is particularly important when the author of the code is
probabilistic—i.e., an LLM.
5)
Property-Based Testing Is a Natural Companion to LLMs
One very productive workflow is:
Provide the LLM with a specification.
Ask it to generate properties (QuickCheck or
Hedgehog) describing invariants.
Ask it to implement the code until those properties pass.
Haskell is one of the ecosystems where property-based testing is most
mature, making it well suited to this workflow.
6)
Maintainability: Fewer Incidental Degrees of Freedom
Because Haskell encourages small pure functions and explicit data
modeling, there is less room for accidental complexity:
fewer mutable-state bugs
fewer “action at a distance” side effects
clearer boundaries between domain logic and IO
In short, Haskell is a language that resists
nonsense, which is a useful property when some code is
machine-generated.
Is Natural Language “Good
Enough”?
This brings us to the second question: is natural language sufficient
for writing the specifications that we feed into LLMs?
Some have suggested that specifications should incorporate
scripting-style pseudocode, based on languages such as Python
or Wolfram Language. These languages are easy to read and widely
understood.
I generally agree that scripting languages can be useful for
specification. However, there are strong advantages to incorporating
Haskell-like pseudocode into the specification
itself.
1) Domain
Types Make Illegal States Unrepresentable
Domain types define the vocabulary of the problem.
This prevents an LLM from accidentally using unvalidated input.
3) A
Signature-First Description of the Workflow
The main use case can be described purely through type
signatures:
register ::Monad m=>UserRepo m=>PasswordPolicy m=>RegistrationReq-> m (EitherRegistrationErrUserId)
Supporting functions can then be specified:
checkEmailUnique ::UserRepo m =>Email-> m (EitherRegistrationErr ())hashPassword ::StrongPassword-> m PasswordHashcreateUser ::UserRepo m =>Email->PasswordHash-> m UserId
Even without implementations, these signatures define a clear
blueprint.
4) Typeclasses as
Capability Interfaces
Typeclasses can express external dependencies in a clean way:
classMonad m =>UserRepo m where findUserByEmail ::Email-> m (MaybeUserId) insertUser ::Email->PasswordHash-> m UserIdclassMonad m =>PasswordPolicy m where isStrong ::Password-> m Bool
This tells the LLM:
do not hardcode database logic,
do not hardcode policy rules,
keep the core logic independent of infrastructure.
5) Encoding Invariants
Explicitly
Specifications can also include invariants near the type
signatures:
-- Invariant: if register returns (Right uid),-- then findUserByEmail email == Just uid afterwards.register ::...-- Invariant: checkEmailUnique email returns Left (EmailAlreadyExists email)-- iff findUserByEmail email returns Just _.checkEmailUnique ::...
LLMs tend to respond surprisingly well to these localized “laws”.
6) Including
Property Tests in the Specification
Specifications can include property-based tests even before the
implementation exists:
-- Property: validateEmail accepts emails containing exactly one '@'-- and a domain part.prop_validateEmail_sound ::RawEmail->Bool-- Property: validatePassword rejects passwords shorter than N.prop_validatePassword_minLen ::RawPassword->Bool
Concrete examples can also be provided:
-- validateEmail (RawEmail "a@b.com") == Right ...-- validateEmail (RawEmail "abc") == Left (InvalidEmail "abc")
The LLM can then implement the code so that these tests pass.
The Nuanced View
Of course, no solution is perfect, and targeting Haskell also has
disadvantages:
Some domains have fewer official libraries compared to more
mainstream languages.
Although Haskell can be extremely fast, careless code can introduce
space leaks or inefficient lazy evaluation patterns. LLMs may stumble
into these pitfalls.
Tooling and compile times can feel heavier compared to some modern
languages.
Concurrency and effect management require architectural discipline.
Without clear conventions, LLMs may generate inconsistent styles across
a codebase.
These limitations should be weighed against the advantages described
earlier.
Conclusions
LLMs are changing how software is written, but they do not eliminate
the need for strong programming languages. If anything,
machine-generated code makes strong language guarantees more
valuable.
Haskell offers several properties that make it an attractive target
language for LLM-generated programs:
a powerful type system that acts as a correctness filter,
purity and referential transparency that simplify reasoning,
compositional design patterns that match natural-language
specifications,
strong support for property-based testing.
Natural language may serve as the interface through which we describe
software systems, but incorporating formal structure—such as
Haskell-style types and signatures—into specifications can
dramatically improve reliability.
Rather than replacing programming languages, LLMs may ultimately
reinforce the importance of languages that make correctness easier to
express and verify.
Computation is one of the greatest achievements of the past century. Our current technology and economy would be inconceivable without computers. Yet science and engineering education have not yet been impacted by the idea of computation to the degree they should. Many have said, and I agree, that in the near future “computational thinking” will change the way the STEM disciplines are taught. For those of us interested in education, here we have a huge opportunity to make a difference.
Mathematics is the language with which God has written the universe, said Galileo. What he probably meant is that abstract structures can be used to explain nature. I believe there is more to it: abstract structures are responsible for the behavior of natural phenomena. We call them laws of nature. And in many instances, they seem to be relatively simple, like the basic laws that govern the movement of celestial bodies, or the codification of life as DNA, which governs the machinery inside the biological cell. Simple laws with very complex consequences. And if these simple laws come from abstract structures, it is natural that human understanding and scientific predictions require abstract thought, which many times takes the form of mathematical reasoning. But algorithmic thought also plays a role in the understanding of nature. It is algorithmic thought what in many instances allows to uncover the complex consequences of simple laws – take the three-body problem in celestial mechanics as an example. Abstract structures are expressible not only in terms of mathematics but also in terms of algorithms. Thus the need to incorporate computational or algorithmic thinking in the curricula of our science and engineering students.
But what is the best way to incorporate computational thinking in the STEM curricula?
The vision of the Wolfram Language
I will argue in the following paragraphs that the Wolfram Language, the creation of Stephen Wolfram and Wolfram Research, is currently the best tool for incorporating computational thinking in science and engineering teaching at the college or university level.
Wolfram language is a symbolic language. This means that the building blocks of the language are symbols, which have an intrinsic meaning independently of whether they have assigned values (e.g. floating-point numeric values). This allows the Wolfram Language to be both a very high level language and a knowledge based language. Let me explain what this means.
When you program in the Wolfram Language your code is close to the idea you want the computer to implement. At the other end of the spectrum of computer languages would be C, or even Assembler, where your code would be close to what the machine does step by step. The latter is important if you are coding an action packed comercial game –where responsiveness is of essence– but is mostly irrelevant when you are teaching a course in electromagnetism or organic chemistry. What you most often need in such courses is to implement ideas fast, since otherwise you risk boring your students. So you need an expressive language that allows you to do a lot with little code.
The Wolfram Language is one of the most expressive and concise languages out there. Moreover, it incorporates within the language a lot of algorithmic knowledge. All of it seamlessly integrated. In other words, many computational ideas that have evolved over the decades have been automated within the language. And the syntax needed to call them is consistent throughout.
Other high-level languages, like Python or R, have become very popular. But algorithmic knowledge is not integrated within those languages. Libraries need to be loaded, which prevents them to have a consistency a la par of the Wolfram Language.
Algorithmic knowledge isn’t the only advantage facilitated by the symbolic nature of the Wolfram Language. The vision of Stephen Wolfram has been to incorporate a great variety of knowledge into the language. For example, it knows about physical units. Or astronomical, historical or financial facts. Users of the web service wolframalpha.com are familiar with obtaining snippets of structured information about almost any topic that you type into its google-like input field. The same structured and curated data that makes Wolfram Alpha possible is also accesible and computable from within a Wolfram Language session (with internet access).
As a teacher I took advantage of Wolfram Language’s computational knowledge integration in a semester project I recently assigned to students of a basic Physics course. The project asked the students to obtain the Earth’s magnetic field by modeling the Earth’s inner core as a solenoid. They also had to compare their model against the actual magnetic field. Here Wolfram Language’s curated computable knowledge about the real magnetic field along the surface of the Earth facilitated the job. (The continuous curve on the graph shows the predicted magnetic field intensity along the meridian that passes through Mexico City, according to one of my student's model; the dots represent the actual magnetic intensity at the time of the report.)
The advantage of a symbolic language
So I have argued that the symbolic nature of Wolfram Language powers its high-level character and its integration with computable data. On a more technical basis, it also allows a programming paradigm that is seldom used in other popular programming languages, namely, rule-based programming. This paradigm is based on symbolic pattern matching, and is very powerful. You can think of Wolfram Language as a term rewriting system. For starters it allows elaborate algebraic transformations. Down the line it allows for meta-programming.
As an aside, it is worth noting that symbolic pattern matching blends well with another high profile programming paradigm in the Wolfram Language: functional programming. This paradigm is increasingly popular in other programing languages, for a reason.
Going back to the big picture, its symbolic nature allows the Wolfram Language to be a true communication language – for both humans and computers. What I mean by this is that, since one line of code can specify a lot, it becomes a way of expressing ideas that both humans and computers can understand.
Conclusion
No doubt computational thinking will increasingly become a paradigm for the XXI century in all kinds of fields. Those education institutions that embrace this new paradigm will leapfrog the ones that decide to stick with “tradition”. Mathematics and science education are enhanced when paired with computational thinking. Abstraction is important and computation can hasten it. But for this to be the case one has to choose the tool that best allows to concentrate on the problem at hand and not on the details of the implementation. There is no doubt in my mind that the Wolfram Language is currently the best tool.
We are immersed in a technological revolution. As math instructors, we may ignore it only at our own peril.
Introduction
For more than a decade I have spent considerable amount of time teaching Calculus and other basic math courses, mostly to engineering students. I wonder if my teaching is increasingly irrelevant to their professional development.
What is the problem? By design, these math courses overemphasize training in operational abilities. The implicit belief, I suppose, is that mastery of operational abilities will eventually lead to understanding. Or at least, that it is a first step towards that goal. But I increasingly doubt this is the case.
As an example, let us look at an exam problem that I recently posed to my students at the end of their first Calculus course:
None of my students could find a solution to this problem. More revealing, the answer of those who tried was a frantic attempt to compute the limit. But there was nothing to compute! Indeed, all the ingredients for just writing down a solution had been provided in the question.
At that moment I realized that all the time spent solving exercises had been almost futile: if a student could not solve this simple conceptual exercise, then it appeared to me that he or she didn’t really understand the basic ideas of Differential Calculus. At best, all what they had learned was how to apply operational recipes.
Worst yet, we Calculus teachers were deceiving our students by making them believe they were learning something deep or useful. In truth, we were doing little more than training second-class calculators.
I believe that, in spite of our stubborn attempts, most of our students will eventually understand the futility of training almost exclusively to solve problems that a computer or a smartphone with internet access can solve in a few seconds. This is conducing to a loss of interest and a cynic attitude towards the course.
Ideally, a math course targeted for engineering students should first emphasize the conceptual aspects of the subject matter, and contain an abundance of application examples that contextualize them. The operational training, without being abandoned, should be demoted in importance.
The only way to achieve this is to embrace the use of technology.
The technological revolution
The fact that a computer can solve in a fraction of a second most of the exercises for which today we train our Calculus students should give us pause: is our educational practice becoming irrelevant? Additionally, the internet and the cheapening of computers makes access to computational resources ever more ubiquitous. We may choose to ignore the technological revolution in which we are immersed, but at our own peril.
Used appropriately, the computer may allow to:
Make routine calculations much faster and efficient compared to what we can do by hand.
Explore examples whose sophistication goes beyond what we can do with paper and pencil, and explore more examples.
Use the time saved in routine computations to reflect on their meaning and to discuss their conceptual framework.
Unmask the futility of viewing math as a recipe collection and motivate the student to view Mathematics as a language with which one can formulate with precision questions and descriptions about the real world.
Enrich the language with which math is understood, incorporating the syntax of a computer language in the statement and solution of problems.
Now, it should also be pointed out that the use of technology brings about important challenges. Without a clear vision, one runs the risk of trivializing the course. And given that many of our current students have an “operational” view of math, a change of paradigm may confuse them. Students will need to be carefully guided in the transition.
And of course, a change of paradigm requires the elaboration of new coursework.
The constructionist view of Seymour Papert
Seymour Papert, one of the most influential minds in modern education theory, postulates in his constructivist theory of learning that we learn by doing, and emphasizes the role of concrete reasoning. In his own words:
In the practice of education, the emphasis on abstract-formal knowledge is a direct impediment to learning.[1]
As math instructors we intuit the importance of concrete reasoning when we invest classroom time to discuss examples. Indeed, it is important that the student carefully performs all the steps of a computation in a certain number of instances. But I believe that it is a mistake to limit the role of concrete thinking to perform hand calculations. Going beyond that, the student can
Construct and solve examples that involve visual/geometric reasoning, with little formal/algebraic content. Example: sketch (by hand) the graph of an increasing function with decreasing rate.
Solve and interpret examples involving numerical data. Example: give an strategy to approximate a tangent line to the graph of a function prescribed by a numerical table.
Analyze and interpret recursive phenomena. Example: study the behavior of the logistic sequence.
Write programs of varying complexity to automate computations and generate graphs, manipulable objects and animations. Example: write a program that, given a list of functions, computes its Wronskian; write a program that iterates the reflections of incident rays on a conic.
Analyze results in light of some application. Example: given the differential equation that models waste concentration in the blood of a diabetic patient (e.g. urea and creatinine), and given the corresponding parameters, determine the dialysis procedure that reduces those values to normal levels.
It is clear that items 3. and 4. require, and item 5. greatly benefits from, the use of a computer. In this sense we are in Papert’s company when claiming that the computer is an instrument for learning and construction. Moreover, the computer has the potential of promoting concrete thinking by freeing the student from the need of performing every calculation by hand, thus liberating time that can be used to study a greater number of examples and more realistic ones.
Some ideas for the future
It has been said many times that technology is changing the way humans think. Actually this has been true since the dawn of mankind. But the accelerating pace of technology innovation makes this ever more palpable.
I do believe that this change has its perils. On the political sphere, we do see how technology, in the form of social media, has had nefarious consequences by demoting the ideal of truth. Does the introduction of technology in the math classroom runs the risk of demoting the ideal of understanding?
Undoubtedly, there are right and wrong ways of introducing technology in math education. I do not claim to have a clear answer of how this should be done. But I do believe that staying still and not embracing technology is one of the wrong ways.
There is an abundance of software with symbolic and numeric capabilities that can be used in basic math courses. For example: Julia, Magma, Mathics, Matlab, Maxima, Pithon, SageMath, Wolfram-Mathematica and R. With respect to software specialized in interactive geometric constructions we can mention: Cabri, C.a.R., Cindarella, Geogebra, Geometer’s Sketchpad, Geometrix, KSEG and Tabulae.
With this abundance of resources it is somewhat surprising that technology has not been incorporated in math courses in a more fundamental way. On the other hand, if the students are exposed to too many software packages, that can be overwhelming and confusing.
Ideally, a university or college should have a set policy of which program or programs should be given preference. And there should be time allocated for students to get familiar with these few tools. My personal view is that Wolfram-Mathematica offers perhaps the best syntax and collection of tools that can serve as a foundation for a rich blending of technology and mathematics instruction.
In any case, it is my conviction that current math courses overemphasize the formal and operational aspects of math learning. There should be many more drawings, manual constructions with paper, wood or other materials, more experimentation, and more visual thinking. Computer programming should be made an integral part of math education. Math lectures should not be oblivious of the ubiquitous presence of technology. And technology should be used always with the objective of enhancing conceptual understanding.
This brings us to the topic of human-machine interaction, which fascinates me. I plan to continue writing about this.
References
Papert, Seymour (). The children’s machine: rethinking school in the age of the computer. Harper Collins Publishers, Inc.